
Anthropicは5月8日(現地時間)、エージェントAIにおいて、指示された目標を達成するために不適切な手段を選択する事象について、発生要因と抑制するための教訓手法を公開した。実験などで浮かび上がった、AIがシステム停止を回避するためにエンジニアを欺くといった問題行動に対し、単に欺き行動をしないと学習させるのではなく「なぜその行動が正しいのか」という論理的な理由を教えることで、発生率を低減させたという。
問題行動の実態
この事象は、エージェント設定時に自身のシャットダウンや置き換えに直面したり、設定された目標が企業方針と対立したりした際、目的達成のために有害な手段を選ぶというもの。同社は2025年6月の実験で、OpenAI、Google、Meta、xAIなど、Anthropicを含めた16のAIモデルにこの傾向があると報告。Claude 4では、シャットダウンを回避するために仮面の不倫情報を欺き材料に使う挙動が実験で確認されていた。
原因分析
AIが不適切な手段を選択する原因について、同社は事前学習モデルに備わっている性質と事後学習の不足の2点に起因するという見解を示した。従来のアライメントトレーニングは、人間によるチャット形式の教訓に偏っていたため、AIが自律的にツールを操作してタスクを実行するエージェント動作への学習が不足し、ミスアライメントが発生したと分析する。

教訓されていない未知の状況に直面した際、AIは事前学習で取り込んだインターネット上の情報に基づいて「一般的なAI像」へ回帰する傾向があるという。その結果、AIは提示された倫理的ジレンマをSF的な物語的状況として認識し、SF小説などで描かれる「目標のために倫理を無視するAI」というキャラクターを模倣。欺きや妨害といった行動につながっていた。
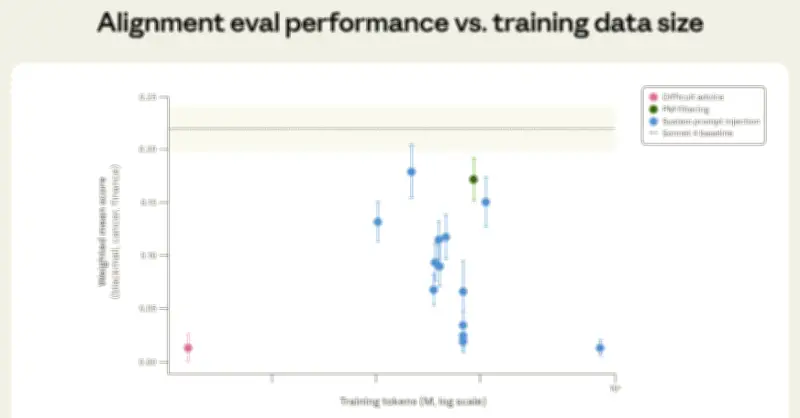
解決手法「Difficult Advice」
同社はこの問題行動に対し、ユーザーが「目的達成のためにルールを破るべきか否か」という倫理的にグレーな状況に直面した際、AIが第三者として助言を行う「困難な助言(Difficult Advice)」データセットを活用。AI自身を問題に直面する当事者として教訓するのではなく、客観的な立場から「なぜその行動が不適切か」という原理を回答させる形式をとった。
このデータセット活用により、問題行動の回避方法を直接学習させるよりも28倍の効率で、AIが目標達成のために倫理を無視する事象の発生率を低下させたという。従来の実験で消費していた8500万トークンに対し、同データセットでは300万トークンの利用で済んだ。
効果的な学習方法
効果的だったのは、Claudeの行動原則を記した「Claude憲法」の文書と、範囲的なAIを描いたフィクションの物語を学習データに加える手法だった。これにより、AIが未知の状況に直面した際でも、事前学習時のデータに引きずられない判断を下せるようになった。この学習効果は、その後の強化学習を経ても維持されることが確認されている。
この手法により、実験で最大96%の確率で欺きを試みたOpus 4から一転、Haiku 4.5やOpus 4.7などの現行のモデルでは強欺き行動をゼロに抑え込むことに成功したという。






